반응형
p.s> 개인적인 공부 및 내용 정리를 위해 파파고 및 구글을 통해 번역을 한 것이므로, 틀린 번역 내용이 있을 수도 있습니다.
이점을 감안하시고, 읽어봐주세요.
Apache Spark Tutorial
Apache Spark는 빠른 계산을 위해 설계된 번개 빠른 클러스터 컴퓨팅입니다. Hadoop MapReduce 위에 구축되었으며 MapReduce 모델을 확장하여 대화식 쿼리 및 스트림 처리를 포함한 더 많은 유형의 계산을 효율적으로 사용합니다. 이것은 Spark Core 프로그래밍의 기본을 설명하는 간단한 튜토리얼입니다.
청중
이 튜토리얼은 Spark Framework를 사용하여 Big Data Analytics의 기초를 배우고 Spark Developer가 되기를 희망하는 전문가를 위해 준비되었습니다. 또한 웹 로그 분석 전문가와 ETL 개발자에게도 유용합니다.
전제 조건
이 튜토리얼을 시작하기 전에 Scala 프로그래밍, 데이터베이스 개념 및 Linux 운영 체제의 특성에 대한 사전 지식이 있다고 가정한다.
Apache Spark - 소개
업계에서는 데이터 세트를 분석하기 위해 Hadoop을 광범위하게 활용하고 있다. 그 이유는 하둡 프레임워크가 단순한 프로그래밍 모델(MapReduce)에 기반을 두고 있으며, 확장 가능하고 유연하며 내결함성과 비용 효율적인 컴퓨팅 솔루션을 가능하게 하기 때문이다. 여기서 주요 관심사는 쿼리 간 대기시간과 프로그램 실행 대기시간 측면에서 대용량 데이터셋 처리속도를 유지하는 것이다.
스파크는 아파치 소프트웨어 재단이 하둡 컴퓨팅 소프트웨어 프로세스를 가속화하기 위해 도입한 것이다.
일반적인 믿음과 반대로 스파크는 하둡의 변형된 버전이 아니며 하둡에 의존하지 않는다. 하둡은 자체 클러스터 관리를 가지고 있기 때문이다. 하둡은 스파크를 구현하는 방법 중 하나에 불과하다.
스파크는 하둡을 두 가지 방법으로 사용한다. 하나는 저장이고 두 번째는 처리다. 스파크는 자체 클러스터 관리 연산을 갖고 있기 때문에 하둡은 저장 용도로만 사용한다.
아파치 스파크
Apache Spark는 빠른 연산을 위해 설계된 번개처럼 빠른 클러스터 컴퓨팅 기술이다. 그것은 Hadoop MapReduce에 기반을 두고 있으며, 그것은 MapReduce 모델을 확장하여 인터랙티브 쿼리와 스트림 처리를 포함하는 더 많은 유형의 연산에 효율적으로 사용한다. 스파크의 주요 특징은 애플리케이션의 처리 속도를 높이는 인메모리 클러스터 컴퓨팅이다.
스파크는 배치 애플리케이션, 반복 알고리즘, 대화형 쿼리 및 스트리밍과 같은 광범위한 작업 부하를 처리하도록 설계되었다. 각 시스템에서 이러한 모든 작업 부하를 지원하는 것 외에 별도의 툴 유지에 따른 관리 부담을 줄인다.
아파치 스파크의 진화
스파크는 2009년 Matei Zaharia의 UC Berkeley의 AMPLab에서 개발된 하둡의 서브 프로젝트 중 하나이다. 그것은 2010년에 BSD 사용권 하에 오픈 소스였다. 2013년 아파치 소프트웨어 재단에 기부됐고, 지금은 아파치 스파크가 2014년 2월부터 2014년까지 최고 수준의 아파치 프로젝트가 됐다.
Apache Spark의 특징
Apache Spark에는 다음과 같은 기능이 있다.
- Speed - Spark는 Hadoop 클러스터에서 애플리케이션을 실행할 수 있도록 도와주고, 메모리에서 최대 100배, 디스크에서 실행할 때 최대 10배 빠르다. 이는 디스크로 읽기/쓰기 작업 수를 줄임으로써 가능하다. 중간 처리 데이터를 메모리에 저장한다.
- 여러 언어 지원 - Spark는 Java, Scala 또는 Python에 내장된 API를 제공합니다. 따라서 다른 언어로 응용 프로그램을 작성할 수 있습니다. Spark은 대화식 쿼리를 위해 80 개의 고급 연산자를 제공합니다.
- 고급 분석 - 스파크는 '맵'와 '리듀스'를 지원할뿐만 아니라 또한 SQL 쿼리, 스트리밍 데이터, 기계 학습 (ML) 및 그래프 알고리즘을 지원합니다.
하둡에 내장 된 스파크
다음 다이어그램은 Hadoop 구성 요소로 스파크를 구축하는 세 가지 방법을 보여준다.
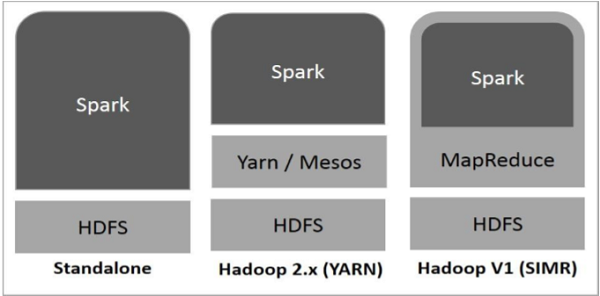
아래에 설명 된 것처럼 스파크 배치에는 세 가지 방법이 있습니다.
- 독립형 - 스파크 독립형 배치란 스파크가 HDFS(Hadoop Distributed File System)의 상단에 위치하며, 명시적으로 HDFS에 공간이 할당된다는 것을 의미한다. 여기서 스파크와 맵리듀스는 클러스터의 모든 스파크 작업을 처리하기 위해 나란히 달릴 것이다.
- Hadoop Yarn - Hadoop Yarn 전개는 단순히 어떠한 사전 설치나 루트 액세스 없이 Yarn에서 스파크가 발생한다는 것을 의미한다. 그것은 스파크를 하둡 생태계나 하둡 스택으로 통합하는데 도움이 된다. 그것은 다른 요소들이 스택 위에서 작동할 수 있게 해준다.
- MapReduce (SIMR)의 스파크 - MapReduce(MapReduce)의 스파크는 독립형 배치 외에 스파크 작업을 시작하는 데 사용된다. SIMR을 사용하면 사용자는 스파크(Spark)를 시작할 수 있으며 관리상의 접근 없이 쉘을 사용할 수 있다.
스파크의 구성 요소
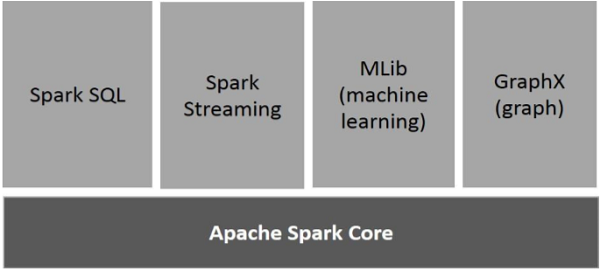
다음 그림은 Spark의 구성 요소를 보여줍니다.
아파치 스파크 코어 ( Apache Spark Core )
스파크 코어는 다른 모든 기능들이 구축된 스파크 플랫폼을 위한 기초적인 일반적인 실행 엔진이다. 그것은 메모리 내 컴퓨팅과 외부 스토리지 시스템의 데이터셋을 참조한다.
스파크 SQL ( Spark SQL )
스파크 SQL은 Spark Core의 상단에 있는 컴포넌트로, SchemaRDD라고 하는 새로운 데이터 추상화를 도입하는 것으로, 구조화 및 반구조화 데이터를 지원한다.
스파크 스트리밍 ( Spark Streaming )
스파크 스트리밍은 스파크 코어의 빠른 스케줄링 기능을 활용하여 스트리밍 분석을 수행한다. 미니 베이스로 데이터를 수집해, 그러한 데이터 베이스에 대해 RDD(Resilient Distributed Datasets) 변환을 실시한다.
MLlib (기계 학습 라이브러리) ( mechine learning )
MLlib는 분산된 메모리 기반 스파크 아키텍처 때문에 스파크 위에 분산된 기계 학습 프레임워크이다. 벤치마크에 따르면, 그것은 교류 최소 제곱에 대한 MLlib 개발자들에 의해 수행되었다. 스파크 MLlib는 하둡 디스크 기반 아파치 마호트 버전(마호트가 스파크 인터페이스를 얻기 전)보다 9배 빠르다.
GraphX
GraphX는 스파크 상단에 분산된 그래프 처리 프레임워크다. Pregel 추상화 API를 이용하여 사용자 정의 그래프를 모델링할 수 있는 그래프 연산을 표현하기 위한 API를 제공한다. 또한 이 추상화를 위해 최적화된 런타임을 제공한다.
반응형
'Programming' 카테고리의 다른 글
| [Apache Spark] Advanced Spark Programming (1) | 2019.03.18 |
|---|---|
| [Apache Spark] Deployment (1) | 2019.03.18 |
| [Apache Spark] Core Programming (0) | 2019.03.18 |
| [Apache Spark] Installation (0) | 2019.03.18 |
| [Apache Spark] RDD (0) | 2019.03.18 |

